为客户维护权益,是我们永远不变的使命!

2024年7月5日,理想汽车在2024智能驾驶夏日宣布会宣布将于7月内向全量理想AD Max用户推送“天下都能开”的无图NOA,并将于7月内推送全自动AES(自动紧要转向)和全方位低速AEB(自动紧要制动)。同时,理想汽车宣布了基于端到端模子、VLM视觉语言模子和天下模子的全新自动驾驶手艺架构,并开启新架构的早鸟设计。
智能驾驶产物方面,无图NOA不再依赖高精舆图或先验信息,在天下局限内的导航笼罩区域均可使用,并借助时空团结设计能力带来更丝滑的绕行体验。无图NOA也具备超远视距导航选路能力,在庞大路口依然可以顺流通行。同时,无图NOA充实思量用户心理平安界限,用分米级微操带来默契放心的智驾体验。此外,即将推送的AES功效可以实现不依赖人辅助扭力的全自动触发,规避更多高危事故风险。全方位低速AEB则再次拓展自动平安风险场景,有用削减低速挪车场景的高频剐蹭事故发生。
自动驾驶手艺方面,新架构由端到端模子、VLM视觉语言模子和天下模子配合组成。端到端模子用于处置通例的驾驶行为,从传感器输入到行驶轨迹输出只经由一个模子,信息转达、推理盘算和模子迭代更高效,驾驶行为更拟人。VLM视觉语言模子具备壮大的逻辑思索能力,可以明白庞大路况、导航舆图和交通规则,应对高难度的未知场景。同时,自动驾驶系统将在基于天下模子构建的虚拟环境中举行能力学习和测试。天下模子连系重修和天生两种路径,构建的测试场景既相符真实纪律,也兼具优异的泛化能力。
理想汽车产物部高级副总裁范皓宇示意:“理想汽车始终坚持和用户配合打磨产物体验,从今年5月推送首批千名体验用户,到6月将体验用户规模扩展至万人以上,我们已经在天下各地积累了超百万公里的无图NOA行驶里程。无图NOA全量推送后,24万名理想AD Max车主都将用受骗前海内*的智能驾驶产物,这是一项诚意满满的重磅升级。”
理想汽车智能驾驶研发副总裁郎咸朋示意:“从2021年启动全栈自研,到今天宣布全新的自动驾驶手艺架构,理想汽车的自动驾驶研发从未住手探索的脚步。我们连系端到端模子和VLM视觉语言模子,带来了业界*在车端部署双系统的方案,也首次将VLM视觉语言模子乐成部署在车端芯片上,这套业内*的全新架构是自动驾驶领域里程碑式的手艺突破。”
无图NOA四项能力提升,天下蹊径高效通行

将于7月内推送的无图NOA带来四项重大能力升级,周全提升用户体验。首先,得益于感知、明白和蹊径结构构建能力的周全提升,无图NOA脱节了对先验信息的依赖。用户在天下局限内有导航笼罩的都会局限内均可使用NOA,甚至可以在更特殊的胡同窄路和墟落小路开启功效。
其次,基于高效的时空团结设计能力,车辆对蹊径障碍物的避让和绕行加倍丝滑。时空团结设计实现了横纵向空间的同步设计,并通过连续展望自车与他车的空间交互关系,设计未来时间窗口内的所有可行驶轨迹。基于优质样本的学习,车辆可以快速筛选*轨迹,武断而平安地执行绕行动作。
在庞大的都会路口,无图NOA的选路能力也获得显著提升。无图NOA接纳BEV视觉模子融合导航匹配算法,实时感知转变的路沿、路面箭头标识和路口特征,并将车道结构和导航特征充实融合,有用解决了庞大路口难以结构化的问题,具备超远视距导航选路能力,路口通行更稳固。
同时,无图NOA重点思量用户心理平安界限,用分米级的微操能力带来加倍默契、放心的行车体验。通过激光雷达与视觉前融合的占用网络,车辆可以识别更大局限内的不规则障碍物,感知精度也更高,从而对其他交通介入者的行为实现更早、更准确的预判。得益于此,车辆能够与其他交通介入者保持合理距离,加减速时机也加倍适合,有用提升用户行车时的平安感。
自动平安能力进阶,笼罩场景再拓展

在自动平安领域,理想汽车确立了完整的平安风险场景库,并凭证泛起频次和危险水平分类,连续提升风险场景笼罩度,即将在7月内为用户推送全自动AES和全方位低速AEB功效。
为了应对AEB也无律例避事故的物理极限场景,理想汽车推出了全自动触发的AES自动紧要转向功效。在车辆行驶速率较快时,留给自动平安系统的反映时间极短,部门情形下纵然触发AEB,车辆全力制动仍无法实时刹停。此时,AES功效将被实时触发,无需人为介入转向操作,自动紧要转向,避让前方目的,有用阻止极端场景下的事故发生。
全方位低速AEB则针对泊车和低速行车场景,提供了360度的自动平安防护。在庞大的地库停车环境中,车辆周围的立柱、行人和其他车辆等障碍物都增添了剐蹭风险。全方位低速AEB能够有用识别前向、后向和侧向的碰撞风险,实时紧要制动,为用户的一样平常用车带来更放心的体验。
并购狂人李东生,杀向家电第三-国际黄金
自动驾驶手艺突破创新,双系统更智能

理想汽车的自动驾驶全新手艺架构受诺贝尔奖得主丹尼尔·卡尼曼的快慢系统理论启发,在自动驾驶领域模拟人类的思索和决议历程,形成更智能、更拟人的驾驶解决方案。
快系统,即系统1,善于处置简朴义务,是人类基于履历和习惯形成的直觉,足以应对驾驶车辆时95%的通例场景。慢系统,即系统2,是人类通过更深入的明白与学习,形成的逻辑推理、庞大剖析和盘算能力,在驾驶车辆时用于解决庞大甚至未知的交通场景,占一样平常驾驶的约5%。系统1和系统2相互配合,划分确保大部门场景下的高效率和少数场景下的高上限,成为人类认知、明白天下并做出决议的基础。
理想汽车基于快慢系统系统理论形成了自动驾驶算法架构的原型。系统1由端到端模子实现,具备高效、快速响应的能力。端到端模子吸收传感器输入,并直接输出行驶轨迹用于控制车辆。系统2由VLM视觉语言模子实现,其吸收传感器输入后,经由逻辑思索,输出决议信息给到系统1。双系统组成的自动驾驶能力还将在云端行使天下模子举行训练和验证。
高效率的端到端模子
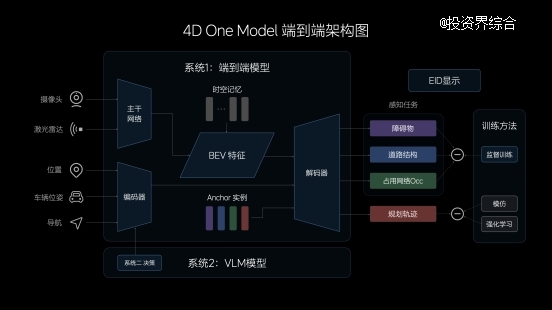
端到端模子的输入主要由摄像头和激光雷达组成,多传感器特征经由CNN主干网络的提取、融合,投影至BEV空间。为提升模子的表征能力,理想汽车还设计了影象模块,兼具时间和空间维度的影象能力。在模子的输入中,理想汽车还加入了车辆状态信息和导航信息,经由Transformer模子的编码,与BEV特征配合解码出动态障碍物、蹊径结构和通用障碍物,并设计出行车轨迹。
多义务输出在一体化的模子中得以实现,中央没有规则介入,因此端到端模子在信息转达、推理盘算、模子迭代上均具有显著优势。在现实驾驶中,端到端模子展现出更壮大的通用障碍物明白能力、超视距导航能力、蹊径结构明白能力,以及更拟人的路径设计能力。
高上限的VLM视觉语言模子
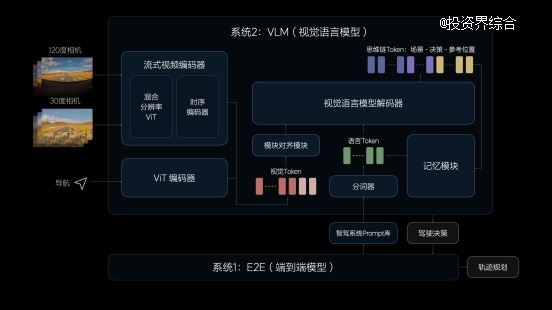
VLM视觉语言模子的算法架构由一个统一的Transformer模子组成,将Prompt(提醒词)文本举行Tokenizer(分词器)编码,并将前视相机的图像和导航舆图信息举行视觉信息编码,再通过图文对齐模块举行模态对齐,最终统一举行自回归推理,输出对环境的明白、驾驶决媾和驾驶轨迹,转达给系统1辅助控制车辆。
理想汽车的VLM视觉语言模子参数目到达22亿,对物理天下的庞大交通环境具有壮大的明白能力,纵然面临首次履历的未知场景也能自若应对。VLM模子可以识别路面平整度、光线等环境信息,提醒系统1控制车速,确保驾驶平安恬静。VLM模子也具备更强的导航舆图明白能力,可以配合车机系统修正导航,预防驾驶时走错蹊径。同时,VLM模子可以明白公交车道、潮汐车道和分时段限行等庞大的交通规则,在驾驶中作出合理决议。
重修天生连系的天下模子
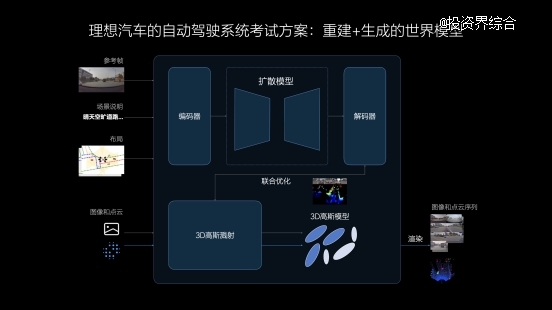
理想汽车的天下模子连系了重修和天生两种手艺路径,将真实数据通过3DGS(3D高斯溅射)手艺举行重修,并使用天生模子弥补新视角。在场景重修时,其中的消息态要素将被星散,静态环境获得重修,动态物体则举行重修和新视角天生。再经由对场景的重新渲染,形成3D的物理天下,其中的动态资产可以被随便编辑和调整,实现场景的部门泛化。相比重修,天生模子具有更强的泛化能力,天气、光照、车流等条件均可被自界说改变,天生相符真实纪律的新场景,用于评价自动驾驶系统在种种条件下的顺应能力。
重修和天生两者连系所构建的场景为自动驾驶系统能力的学习和测试缔造了更优异的虚拟环境,使系统具备了高效闭环的迭代能力,确保系统的平安可靠。
